Rust 编译器的前端现在可以使用并行执行来显著缩短编译时间。要尝试此功能,请使用 -Z threads=8 选项运行 nightly 版本的编译器。此功能目前处于实验阶段,我们计划于 2024 年在稳定版编译器中发布。
请继续阅读,了解为何需要并行前端及其工作原理;或直接跳到 如何使用 部分。
编译时间和并行性
Rust 的编译时间一直是人们关注的问题。编译器性能工作组 多年来持续改进编译器的性能。例如,根据我们的性能测试套件测量,在 2023 年的前 10 个月里,平均编译时间缩短了 13%,峰值内存使用量减少了 15%,二进制文件大小减小了 7%。
然而,目前编译器已经过高度优化,新的改进之处很难找到。不再有唾手可得的成果。
但有一个巨大但难以触及的成果:并行性。当前的 Rust 编译器用户受益于两种并行性,而新增的并行前端则增加了第三种。
现有的进程间并行性
编译 Rust 程序时,Cargo 会启动多个 rustc 进程,并行编译多个 crate。这工作得很好。尝试使用 -j1 标志编译大型 Rust 程序来禁用此并行化,你会发现编译时间会比正常情况长得多。
如果使用 Cargo 的 --timings 标志进行构建,你可以可视化这种并行性,该标志会生成一个图表,显示 crate 是如何编译的。下图显示了在具有 28 个虚拟核心的机器上构建 ripgrep 时的编译时间线。

图中有 60 条水平线,每条代表一个独立的进程。它们的持续时间从不到一秒到数秒不等。其中大部分是 rustc 进程,少数橙色的线条是构建脚本。最开始的二十个进程同时启动,这是因为相关 crate 之间没有依赖关系。但在图表的下方,随着 crate 依赖关系的增加,并行性有所降低。尽管编译器可以通过一种称为 流水线式编译 的特性一定程度上重叠依赖 crate 的编译,但在编译的后期,并行执行会大大减少,这对于大型 Rust 程序来说是很典型的。进程间并行性不足以充分利用多核优势。为了获得更高的速度,我们需要每个进程内部的并行性。
现有的进程内并行性:后端
编译器分为两部分:前端和后端。
前端执行许多任务,包括解析、类型检查和借用检查。直到本周之前,它还不能使用并行执行。
后端执行代码生成。它以称为“代码生成单元”(codegen units)的块来生成代码,然后 LLVM 并行处理这些单元。这是一种粗粒度并行性。
我们可以可视化串行前端和并行后端之间的差异。下图显示了名为 Samply 的性能分析器在 Cargo 中对最终 crate 进行 release 构建时对 rustc 的测量结果。图像上叠加了标记,指示前端和后端的执行。
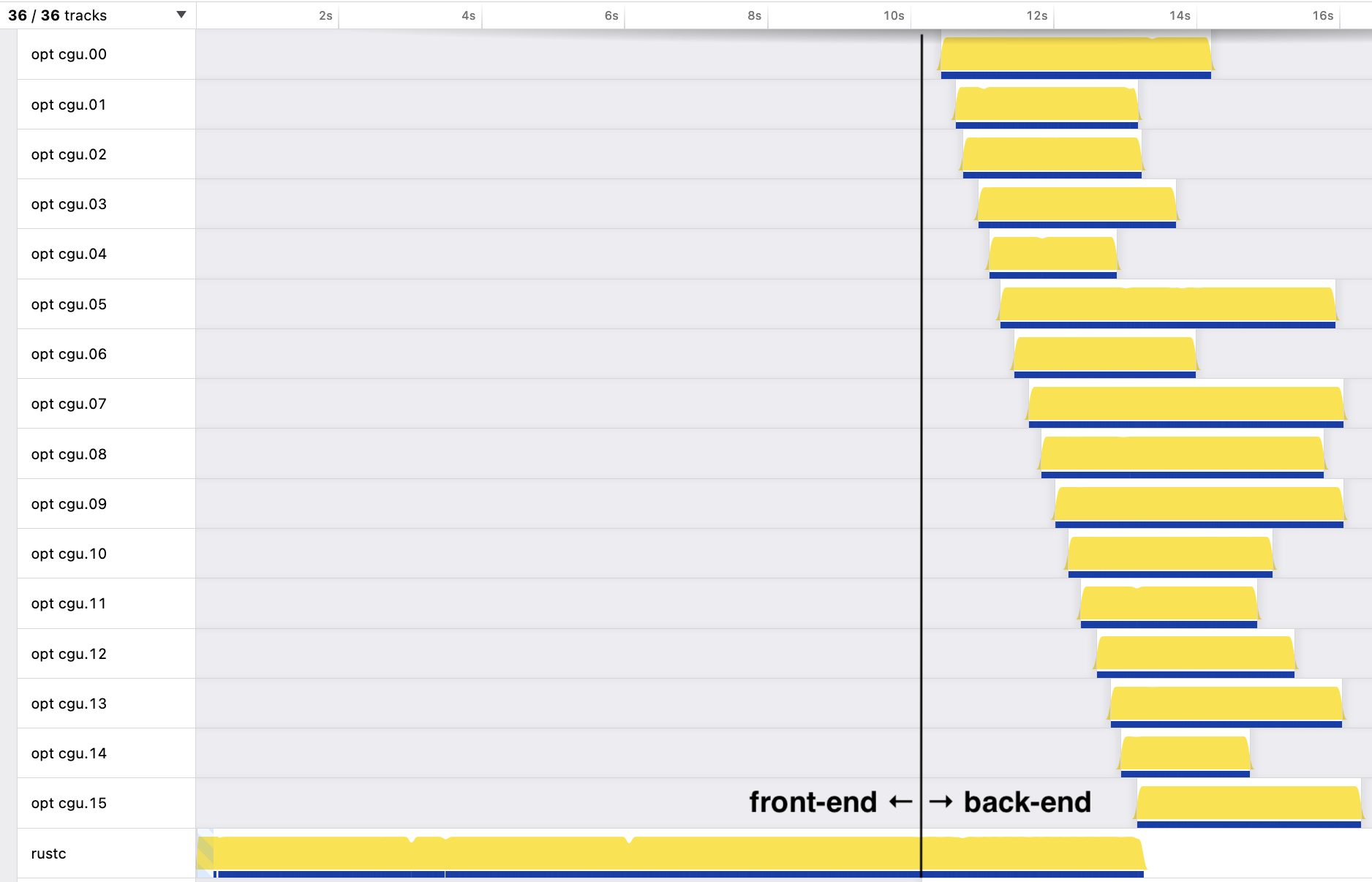
每条水平线代表一个线程。主线程标记为 "rustc",显示在底部。它在大部分执行时间内都很忙碌。另外 16 个线程是 LLVM 线程,标记为 "opt cgu.00" 到 "opt cgu.15"。之所以有 16 个线程,是因为对于 release 构建,默认的代码生成单元数量是 16 个。
有几点值得注意。
- 前端执行耗时 10.2 秒。
- 后端执行耗时 6.2 秒,其中 LLVM 线程运行了 5.9 秒。
- 并行代码生成效率很高。想象一下如果所有 LLVM 线程一个接一个地执行会怎样!
- 即使有 16 个 LLVM 线程,它们也从未全部同时执行,尽管运行在具有 28 个核心的机器上(峰值为 14 或 15)。这是因为主线程串行地将其内部代码表示(MIR)转换为 LLVM 的代码表示(LLVM IR)。每个代码生成单元的转换都需要一小段时间,这解释了代码生成线程左侧的阶梯状形状。这里仍有改进的空间。
- 前端完全是串行的。这里有很大的改进空间。
新增的进程内并行性:前端
前端现在能够并行执行了。它使用 Rayon 库通过细粒度并行性来执行编译任务。许多数据结构通过互斥锁和读写锁进行同步,在适当的地方使用原子类型,并且许多前端操作都已并行化。添加并行性是通过修改代码中相对少量的关键点来实现的。绝大多数前端代码无需更改。
当启用并行前端并配置使用八个线程时,我们在编译与之前相同的示例时得到了以下 Samply 性能分析图。
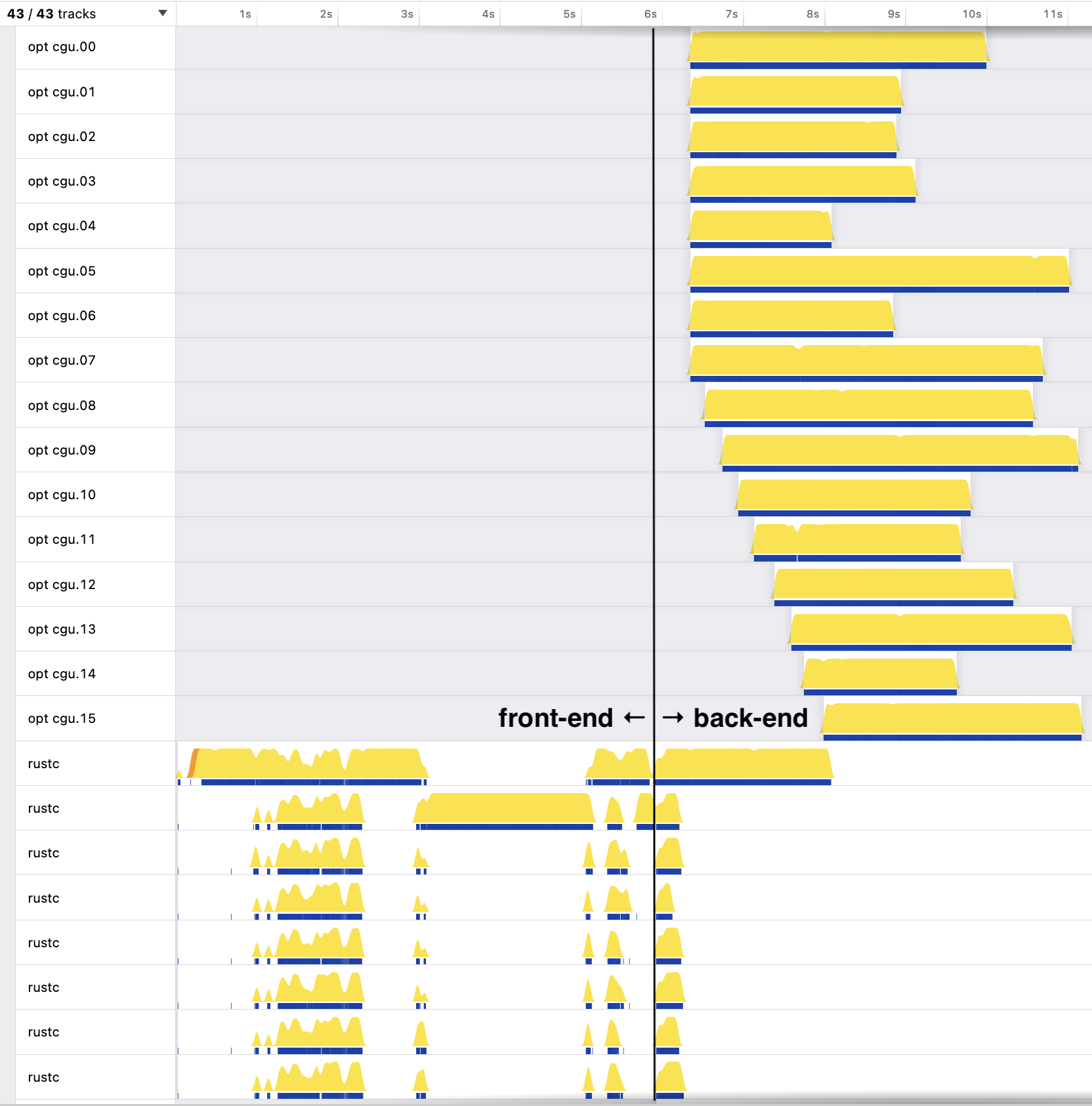
同样,有几点值得注意。
- 前端执行耗时 5.9 秒(从 10.2 秒下降)。
- 后端执行耗时 5.3 秒(从 6.2 秒下降),其中 LLVM 线程运行了 4.9 秒(从 5.9 秒下降)。
- 前端有七个额外标记为 "rustc" 的线程在运行。缩短的前端时间表明它们相当有效,但线程利用率并不均匀,这八个线程都有闲置的时期。这里仍有显著的改进空间。
- 八个 LLVM 线程同时启动。这是因为八个 "rustc" 线程并行地为八个代码生成单元创建 LLVM IR。(对于其中七个线程来说,这是它们在后端做的唯一工作。)在那之后,阶梯效应又回来了,因为只有一个 "rustc" 线程在生成 LLVM IR,而七个或更多的 LLVM 线程处于活动状态。如果前端使用的线程数更改为 16,则阶梯形状会完全消失,尽管在这种情况下,最终执行时间几乎不会改变。
总结
Rust 编译长期以来受益于通过 Cargo 实现的进程间并行性以及后端中的进程内并行性。现在,它也可以受益于前端中的进程内并行性。
你可能会想,进程间并行性和进程内并行性是如何相互作用的。如果我们有 20 个并行的 rustc 调用,每个调用最多可以运行 16 个线程,那么在一台只有几十个核心的机器上,我们是否最终会得到数百个线程,导致操作系统在调度它们时效率低下?
幸运的是,不会。编译器使用 jobserver 协议 来限制它创建的线程数量。如果大量进程间并行性正在发生,进程内并行性将得到适当限制,并且线程总数不会超过核心数量。
如何使用
nightly 版本的编译器现在已 启用并行前端。然而,默认情况下它运行在单线程模式下,并不会缩短编译时间。
热衷的用户可以通过 -Z threads 选项选择多线程模式。例如:
$ RUSTFLAGS="-Z threads=8" cargo build --release
另外,要从 config.toml 文件(针对一个或多个项目)选择启用,请添加以下行:
[build]
rustflags = ["-Z", "threads=8"]
单线程模式成为默认设置可能令人惊讶。为什么将前端并行化却又让它在单线程模式下运行呢?答案很简单:谨慎。这是一项重大改变!并行前端有大量新代码。单线程模式可以测试大部分新代码,但排除了可能影响多线程模式的线程错误(如死锁)的可能性。即使在 Rust 中,并行程序也比串行程序更难正确编写。因此,并行前端在一段时间内也不会包含在 beta 或 stable 版本中。
性能影响
当并行前端在单线程模式下运行时,编译时间通常比串行前端慢 0% 到 2%。这应该几乎无法察觉。
当并行前端在多线程模式下使用 -Z threads=8 运行时,我们对实际代码的测量结果显示,编译时间最多可缩短 50%,尽管效果差异很大,取决于代码的特性和构建配置。例如,dev 构建比 release 构建更有可能看到更大的改进,因为 release 构建通常在后端花费更多时间进行优化。少数情况下,多线程模式下的编译速度会比单线程模式慢。这些大多是本身编译就很快的小型程序。
我们推荐八个线程,因为这是我们测试最多且已知能获得良好结果的配置。小于八个线程的值带来的好处会较小,但如果你的硬件核心数少于八个,则这些值是合适的。大于八个线程的值收益会递减,甚至可能导致性能下降。
如果从一个线程到八个线程只获得了 50% 的改进看起来很低,请回想上面的解释,前端只占编译时间的一部分,而且后端已经是并行的了。你无法克服 阿姆达尔定律。
在多线程模式下,内存使用量可能会显著增加。我们观察到增加量最高可达 35%。考虑到编译的各个部分(每个部分都需要一定的内存)现在正在并行执行,这并不令人意外。
正确性
单线程模式下的可靠性应该很高。
在多线程模式下存在一些已知错误,包括死锁。如果编译挂起,很可能就是遇到了其中一个错误。
无论使用哪个前端,编译器生成的二进制文件应该是一致的。任何差异都将被视为错误。
反馈
如果您在使用并行前端时遇到任何问题,请 查看标记为“WG-compiler-parallel”的现有问题。如果您的问题与现有问题不符,请 提交新问题。
如需提供更普遍的反馈,请在 wg-parallel-rustc Zulip 频道上发起讨论。我们特别有兴趣了解此功能对您关注的代码的性能影响。
未来工作
我们正在努力改进并行前端的性能。如上面的图表所示,前端的线程利用率仍有改进空间。我们也在解决多线程模式下剩余的错误。
我们计划在 2024 年稳定 -Z threads 选项,并在稳定版发布中默认以多线程模式启用并行前端。
致谢
并行前端的开发已经进行了很长时间。它由 @Zoxc 启动,他在最初的几年里完成了大部分工作。经过一段沉寂期后,该项目在今年由 @SparrowLii 重新启动,并由他主导推动了此功能的发布。并行 Rustc 工作组 的其他成员也参与了评审和其他活动。非常感谢所有参与者。